Syllabus: Fractal-U Course on LLMs
Overview and motivations for the Fractal-U LLM Course.
Intro
In this course, we will create our own AI Assistant. The Assistant will be an augmented and fine-tuned open-source Large Language Model (LLM).
So, what exactly is an AI Assistant? And why would we want to make one?
There is a lot of excitement around AI assistants and agents. People are thinking of a future where everyone has powerful, personalized helpers at their fingertips. These future agents promise to make our lives easier and more comfortable. They are the manifest AIs of Science Fiction: TARS from Interstellar, HAL 9000 from Space Odyssey, Iron Man’s Jarvis, etc.
Realistic Assistants
Despite rapid improvements in LLMs, AI Assistants as powerful as those are still a ways off. It is hard, if not impossible, to predict the exact timelines. Perhaps we can safely say that Assistants of that caliber won’t be here anytime “soon.” But, outside of some force majeure, they will exist at some point.
As of writing, there is a large gap between the advanced Assistants of the future, and the hallucinations and steep compute of today’s LLMs.
Building an AI Assistant
The aim of this course it to help close that gap. We have a strong path forward, as this announcement from OpenAI shows: fine-tuning GPT-3.5 on small, clean datasets can surpass GPT-4 on certain tasks.
That’s the kind of Assistant we are aiming for. In other words, we already have the ability to develop powerful AI tools by fine-tuning LLMs on small, clean datasets.
Think of our Assistant like a smart Rubber Duck. A Rubber Duck is some object on our desk that we talk to about our work. It is a physical tool for thought, since it’s so often helpful to speak out loud the swirl of thoughts in our heads.
But it won’t be a silent thing on a desk. Our Assistant will be able to talk with us. When we ask it a question about our work, it will respond given what it knows about the entire project. Or if we are simply verbalizing a thought to untangle it, the Assistant can give us feedback and suggest other ideas.
We are aiming for something far more than a simple chatbot. If we can be so bold: our Assistant will be a mini-Jarvis laser-focused on a specific task.
Course Summary: We will fine-tune and augment an LLM on a small, clean dataset to build an intelligent Rubber Duck.
Course Overview
This course will equip us with a full development workflow to leverage the latest progress in LLMs. Our Rubber Duck will be able to weave in the latest models and techniques.
There are seven total lessons. Each lesson lives inside a Jupyter Notebook. The notebooks do build on each other, but each one is self-contained and reviewable on its own.
Here is an outline of the lessons:
1. Python environments for LLMs
Using mamba and pip to create isolated, reproducible python environments.
2. Blogging with nbdev
Setting up a blog with nbdev and github pages.
3. Running HuggingFace NLP models
Using the HuggingFace API to run NLP models.
4. Running optimized LLMs with llama.cpp
Running quantized, optimized LLMs.
5. Processing text documents for LLMs
Preparing text data for fine-tuning and Retrieval Augmented Generation (RAG)
6. Fine-tuning LLMs on a GPU
Scripts to efficiently fine-tune LLMs
7. Running fine-tuned LLMs locally on your phone
Deploying fine-tuned, quantized LLMs on mobile devices
This is a public-facing course. Students are meant to write about their journey to both track and cement their progress.
Publishing our work casts it under a new, critical light and becomes a powerful tool for learning. Your understanding of a topic is also crystallized by seeing how others approached the same problem.
It is admittedly hard to blog out in the open. But, we hope to make it as easy and rewarding as possible.
Course Philosophy
Jupyter Notebooks are the modern digital versions of field journals. The striking samples below from this Wired article show what science can be, at its best and most alive:
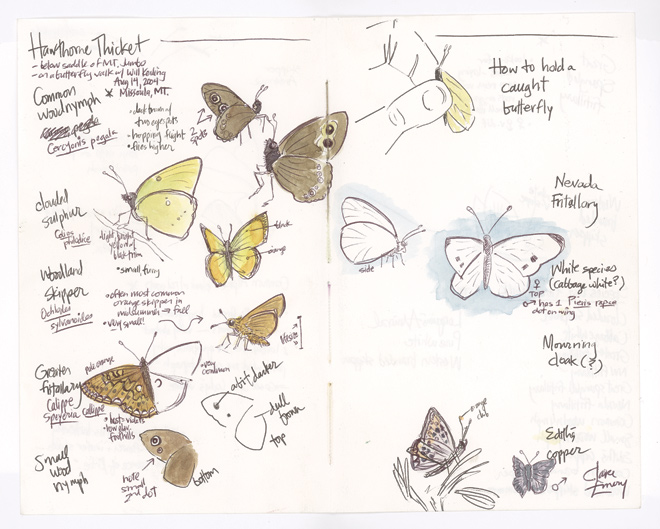
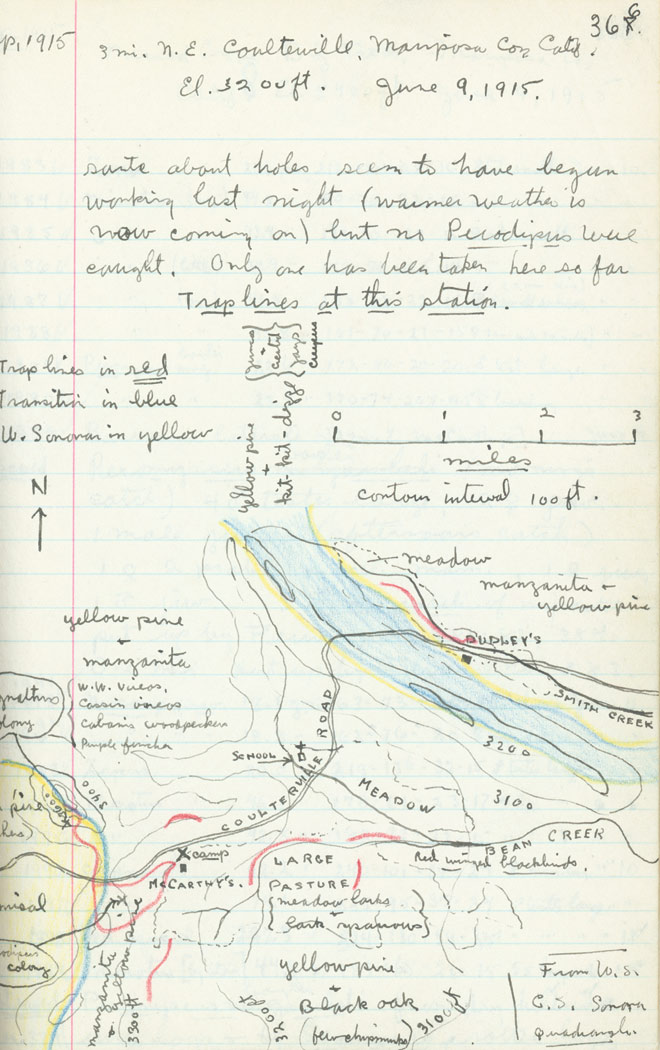

Let’s focus in on the last example: the field notes about a lynx.
Notice how we’re not getting a long description of what a Lynx is supposed to look like. Neither are we looking at a wall of pictures with no context. The field note offers the best of both worlds: short and relevant descriptions next to clear, working examples. Good field notes bridge the gap between the written, theoretical and the actual, practical.
Notebooks do for programming what these field notes did for the lynx. With them, we can interactively describe what’s being done, show people the data, and make sure that the results are correct. We can also, crucially, show any mistakes and struggles along the way.
This tight loop between what we’re doing (code), describing what we’re doing (documentation), and making sure that it’s correct (tests) is a great way to approach research. More importantly, it is an incredibly powerful way to communicate and share ideas.
Each lesson is like an interactive field journal. You should feel as if someone is walking you through an experiment, talking throughout the process. You can also be an active participant by running the code and making changes, or trying new ideas.
Conclusion
This notebook introduced the goals and approach for the Fractal-U LLMs course. To recap: we will fine-tune and augment an open-source LLM to create an AI Assistant that helps us with our creative and educational work.
Thank you for coming along on this journey. In the next notebooks, we will learn a complete workflow to create a powerful Assistant. And we will have tons of fun along the way.